目錄
使用 Python 讀取 S3 中的 Excel 檔,並將資料儲存在 DynamoDB ,本實驗將提供這樣的整合練習:Python SDK + S3 + DynamoDB
AWS Academy Learner Lab 是提供一個帳號讓學生可以自行使用 AWS 的服務,讓學生可以在 50 USD的金額下,自行練習所要使用的 AWS 服務,在此先介紹一下 Learner Lab 基本操作與限制。
在 AWS Academy 學習平台 的入口首頁 https://www.awsacademy.com/LMS_Login ,選擇以學生 (Students) 身分登錄,在課程選單中選擇 AWS Academy Learner Lab - Foundation Services 的課程,在課程選單中選擇 單元 (Module),接著單擊 啟動 AWS Academy Learner Lab,如下圖所示。
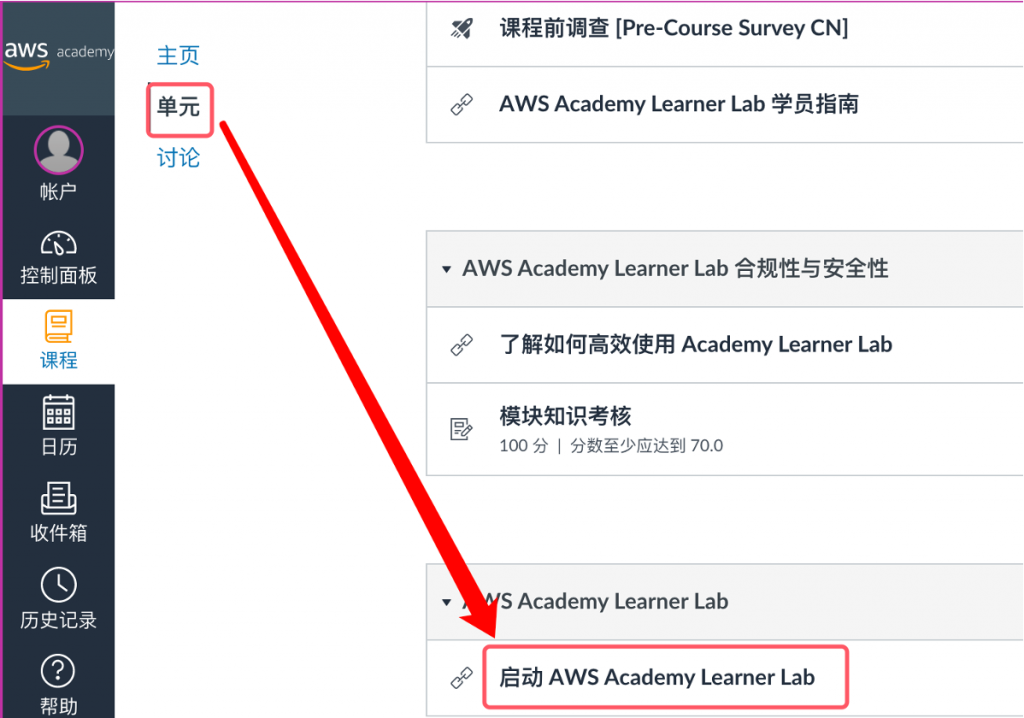
圖 1. 啟動 AWS Academy Learner Lab
進入 Learner Lab 中,說明一下每個區塊,圖形在下方。
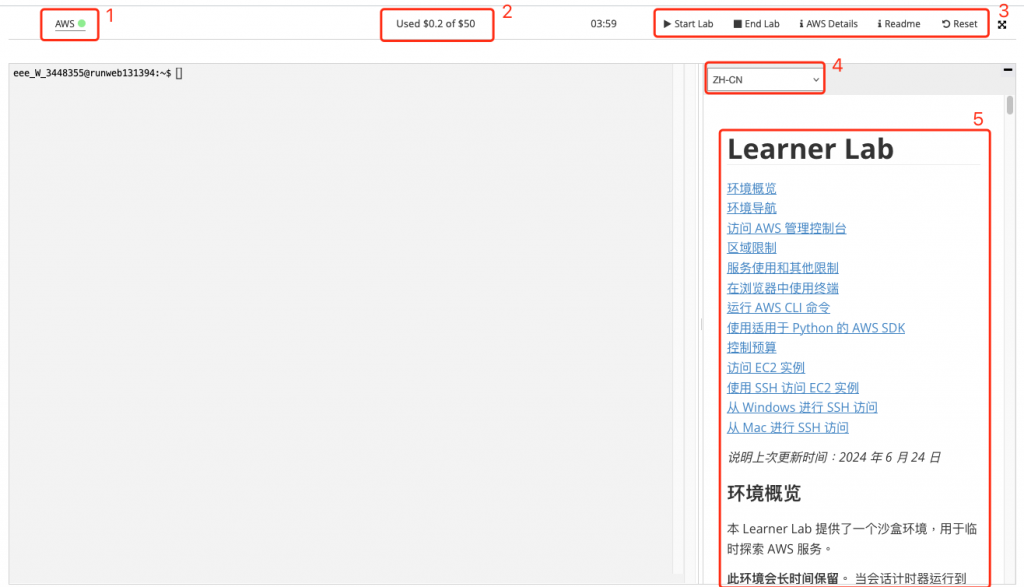
圖 2. Learner Lab 畫面說明
AWS Cloud9 IDE 畫面與 VS Code 畫面相似,左手邊是功能視窗,可以檢視檔案與其他功能;,右上方是檔案編輯畫面,可以進行檔案編輯,撰寫程式進行 AWS SDK 操作;右下方則是終端命令列介面,可以輸入指令,進行 AWS CLI 操作。
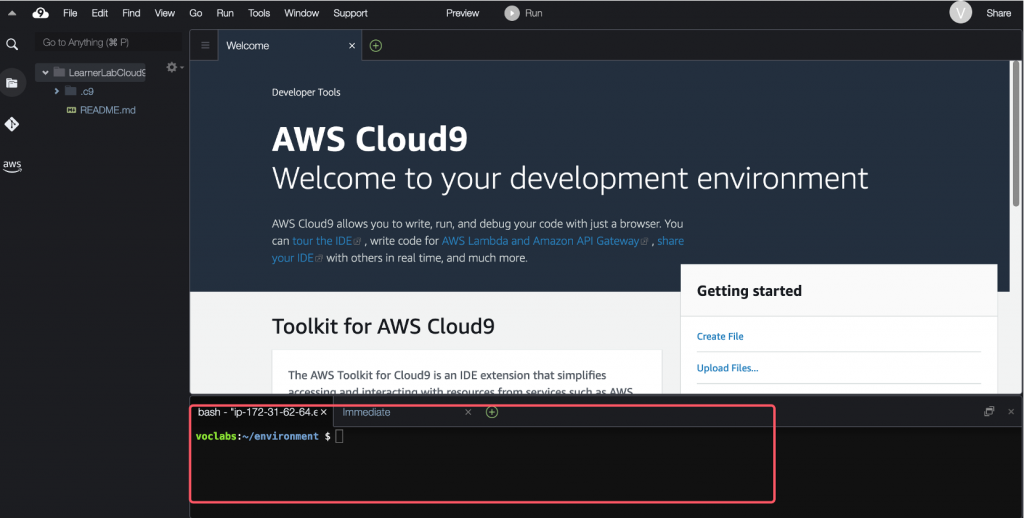
圖 3. AWS Cloud9 IDE
在下方的終端輸入以下指令,取得實驗所需要的資源,可以在左上角看到已下載的檔案。
git clone https://github.com/yehchitsai/AIoTnAWSCloud
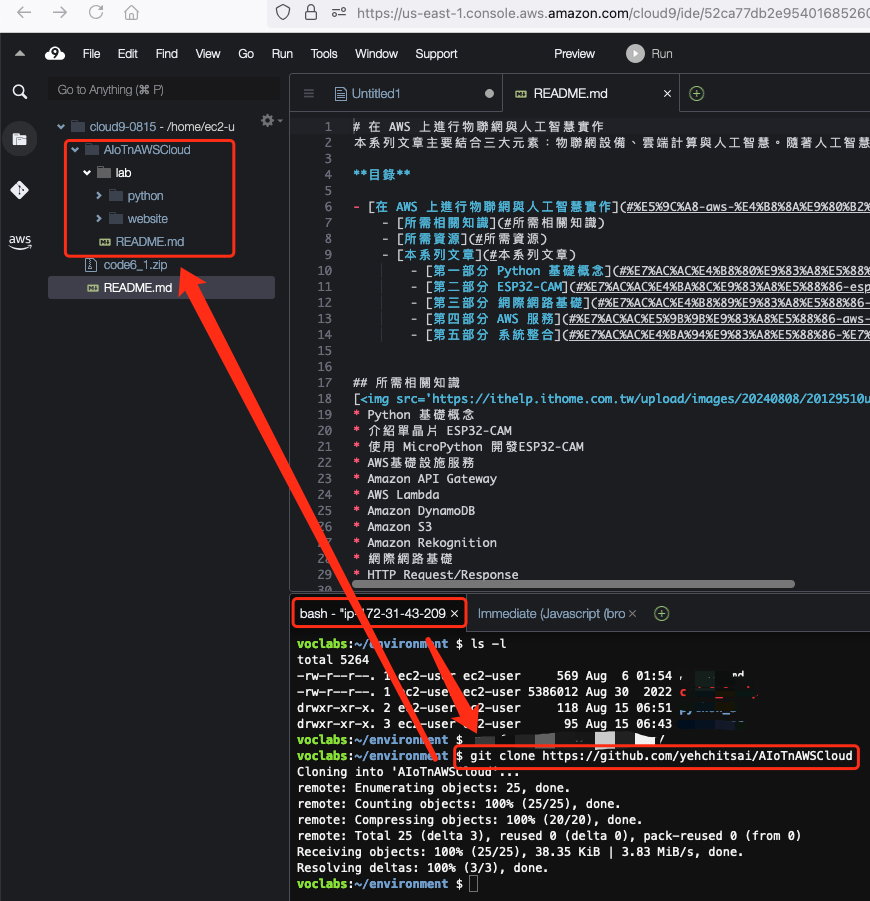
圖 4. 取得實驗所需要的資源
輸入以下 AWS CLI 指令,用來建立 S3 儲存貯體,將 BUCKET_NAME 改為自己所要建立的 S3 儲存貯體名稱。aws s3api create-bucket --bucket BUCKET_NAME
AWS CLI 說明指令:aws [options] <command> <subcommand> [parameters]
而回傳值是建立儲存貯體的名稱。
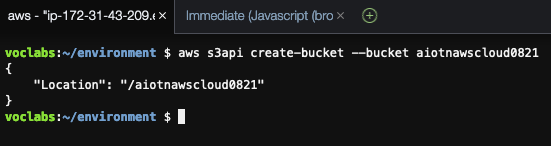
圖 5. 使用 AWS CLI 指令建立 S3 儲存貯體
在下方的終端輸入以下指令,將物件上傳到儲存貯體,將 BUCKET_NAME 改為自己所建立的 S3 儲存貯體名稱。aws s3 cp AIoTnAWSCloud/lab/python/dataset/student_info.xlsx s3://BUCKET_NAME/ --cache-control "max-age=0"
檢查 Cloud9 開發環境的套件版本
| 工具 | 版本 |
|---|---|
| git | 2.40.1 (git -v) |
| AWS CLI | aws-cli/2.17.24 Python/3.11.9 Linux/6.1.102-108.177.amzn2023.x86_64 exe/x86_64.amzn.2023 (aws --version) |
| python | 3.9.16 (python3 -V) |
| boto3 | 1.34.161 (pip list) |
| s3transfer | 0.10.2 |
| openpyxl | 3.1.5 |
| et-xmlfile | 1.1.0 |
| pandas | 2.0.3 |
| numpy | 1.24.4 |
| tzdata | 2024.1 |
| pytz | 2024.1 |
| python-dateutil | 2.9.0.post0 |
為 Python 安裝 pandas 以及可以讀取 excel 檔案的套件,在下方的終端輸入以下指令
pip install pandas openpyxl
打開 AIoTnAWSCloud/lab/python/excel2Lambda.py 並執行,如下圖所示。
該程式會執行三個主要步驟
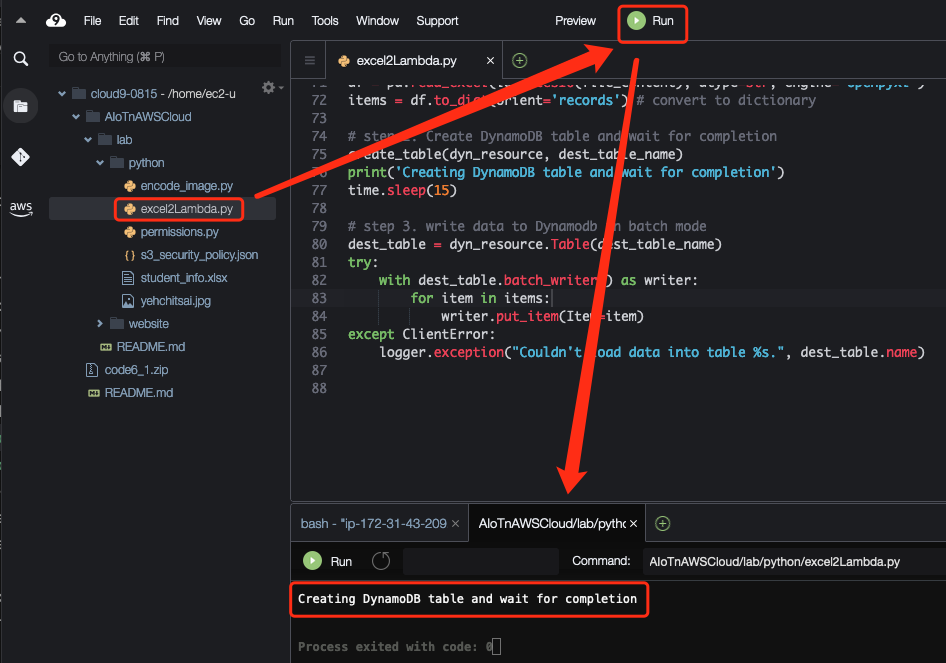
圖 6. 執行 excel2Lambda.py
將 BUCKET_NAME 改為自己所建立的 S3 儲存貯體名稱。
import io
import json
import boto3
import pandas as pd
from botocore.exceptions import ClientError
import logging
import time
dyn_resource = boto3.resource("dynamodb")
logger = logging.getLogger(__name__)
s3_client = boto3.client("s3")
S3_BUCKET_NAME = 'BUCKET_NAME'
dest_table_name = 'students'
object_key = "student_info.xlsx" # replace object key
# check the table whether exists
def exists(dynamodb, table_name):
try:
table = dynamodb.Table(table_name)
table.load()
exists = True
except ClientError as err:
if err.response["Error"]["Code"] == "ResourceNotFoundException":
exists = False
else:
logger.error(
"Couldn't check for existence of %s. Here's why: %s: %s",
table_name,
err.response["Error"]["Code"],
err.response["Error"]["Message"],
)
raise
return exists
# CreateTable, https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_CreateTable.html#API_CreateTable_RequestSyntax
def create_table(dynamodb = None, table_name = None):
try:
if not dynamodb:
dynamodb = boto3.resource('dynamodb')
table = ''
if not exists(dynamodb, table_name):
table = dynamodb.create_table(
TableName = table_name,
BillingMode = "PAY_PER_REQUEST",
KeySchema = [
{
'AttributeName': 'student_id',
'KeyType': 'HASH' # Partition key
}
],
AttributeDefinitions=[
{
'AttributeName': 'student_id',
'AttributeType': 'S'
}
]
)
except ClientError as err:
logger.error(
"Couldn't create table %s. Here's why: %s: %s",
table_name,
err.response["Error"]["Code"],
err.response["Error"]["Message"],
)
raise
else:
return table
# step 1. read excel from S3 object
file_content = s3_client.get_object(Bucket=S3_BUCKET_NAME, Key=object_key)["Body"].read()
df = pd.read_excel(io.BytesIO(file_content), dtype=str, engine='openpyxl')
items = df.to_dict(orient='records') # convert to dictionary
# step 2. Create DynamoDB table and wait for completion
create_table(dyn_resource, dest_table_name)
print('Creating DynamoDB table and wait for completion')
time.sleep(15)
# step 3. write data to Dynamodb in batch mode
dest_table = dyn_resource.Table(dest_table_name)
try:
with dest_table.batch_writer() as writer:
for item in items:
writer.put_item(Item=item)
except ClientError:
logger.exception("Couldn't load data into table %s.", dest_table.name)
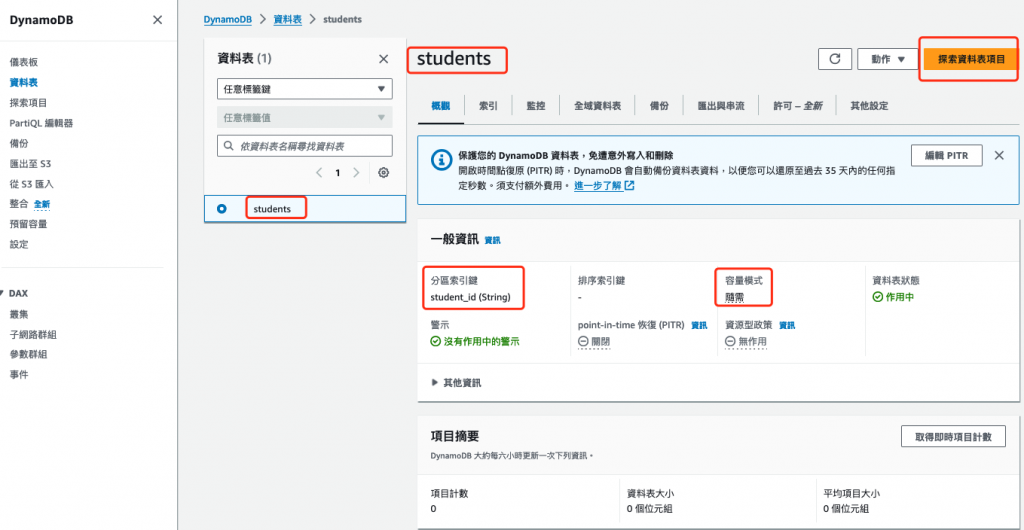
進入 Dynamodb 控制台,找到資料表 students,點擊 students,可以看到資料表詳細資訊
點擊探索資料表項目,檢視資料表項目,可以看到從 excel 所匯入的 3 筆資料
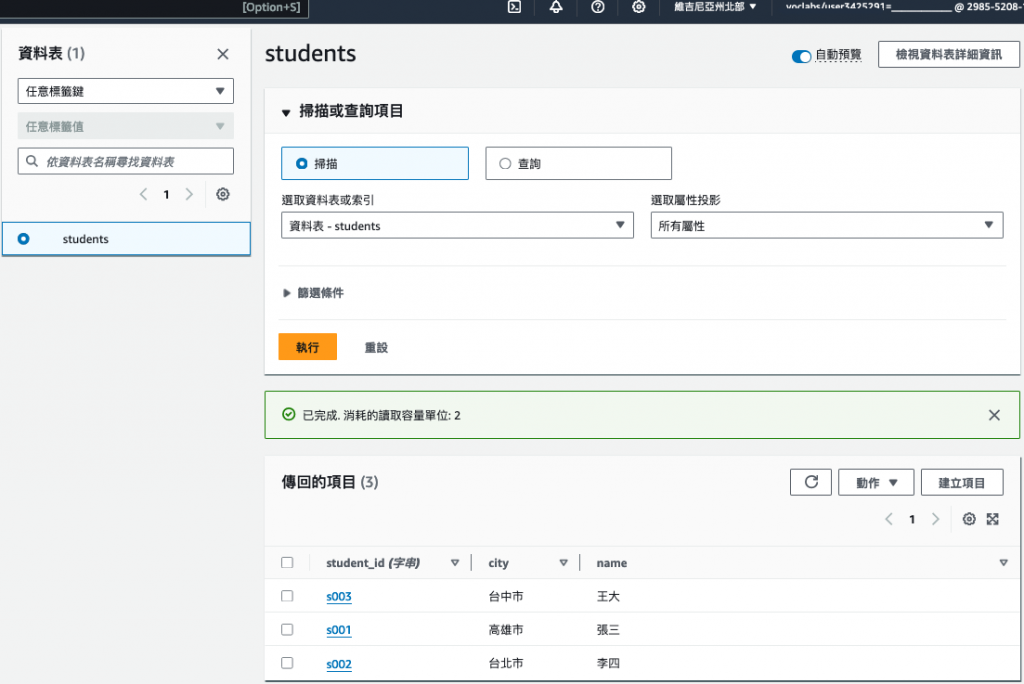
圖 8. students 資料表項目

